
In large enterprises, business workflows often require distributed components for seamless scaling and maintenance. Hence it is essential to develop effective connectivity and communication between such elements. Event-driven architecture plays a vital role in such scenarios.
What is an event?
An event can be described as ‘something that has happened or a significant change in the state’. Events are immutable, i.e. they cannot be changed or deleted, and they are ordered in sequential order of their occurrence. A component for other components creates a notification to inform them about the occurrence of an event. It mainly consists of information about the possibilities and context of their occurrence, such as location, time, etc.
What is event-driven architecture?
An event-driven architecture uses events to trigger and communicate between decoupled services or components. EDA makes it possible to exchange information between the systems in real-time as events occur instead of periodically polling for updates. It is commonly used in many modern applications built using microservices.
Event-driven architectures have three main components:
1) Event producers: publish events to the router
2) Event routers: filters, processes and routes the events to consumers
3) Event consumers: receive the event and take action on them
Producer and consumer in event-driven architecture are decoupled; hence they can be scaled, updated, and deployed independently.
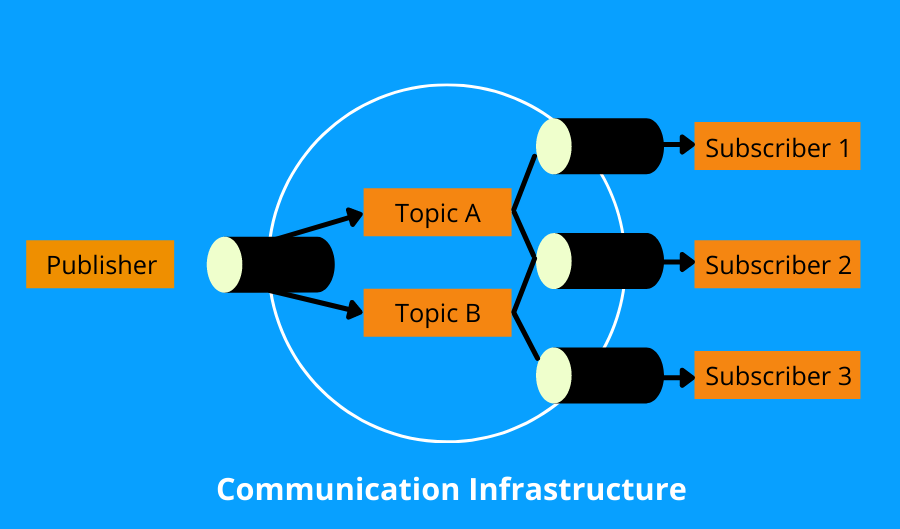
Event-driven architecture is mainly implemented using the publish/subscribe message pattern.
In the publish/subscribe model, consumers are called subscribers and producers are called publishers. Subscribers sign up for the topics/channels of their interest. Publishers publish events to the topics, and the subscribers receive the events that interest them. Hence, this pattern is the most suitable framework for streaming real-time data.
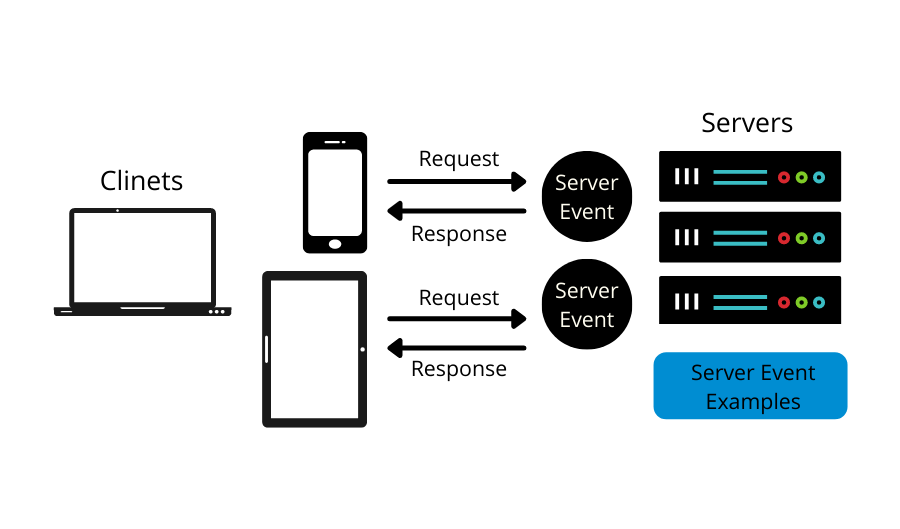
Let us understand event-driven architecture using a real-world example of a food delivery application. You have ordered your favourite food from a restaurant. You are anxiously waiting for the food. Now with the traditional architecture, i.e., request-driven approach, you wouldn't know the status of your order since to get the status you need to send a request. Thus, you will have to click a button on the application, which will update the current status of your order. Therefore, you are periodically polling to get the updated status. The polling, in this case, is very annoying for you and the system; it is costly and consumes a lot of bandwidth with no positive result.
Now let us view this situation with an event-driven architecture approach.
When you order food using your application, a food order event is published. The restaurant which has subscribed to this event receives it and accepts your order. It publishes a status event that your application receives, which then updates the status of your order. So now you can view the status that the restaurant has accepted your order and food is being prepared. When your food is prepared, the restaurant publishes another food-ready event, and the delivery person subscribing to this event picks up the order and starts his ride. Simultaneously order status on your application is updated. An event is triggered with each update in the rider’s location, and you are updated in real-time. Thus with this approach, you know the current status of your order without continuously polling for the same.
Benefits of EDA:
Loose coupling: Systems using EDA have components that are loosely coupled. This decoupling helps in the logical separation of production and consumption of events. Producers are not concerned with how the events are consumed, whereas consumers are not worried about producing the events. Because of this loose coupling, different components or microservices can be developed in other languages or use different technologies. It also helps in application scaling. Producers or consumers can be added or removed as per the requirements without any logical change in other components.
Fault tolerance: Eventing is asynchronous, which infers that events are published as and when they happen. Event consuming service or component subscribes to these events. So when any consumer goes down, the application will continue running in its absence. Events are queued in the broker so that when the consumer recovers from the failure, it can pick up the pending events.
Better real-time user experiences: Event-driven APIs lead to a better interactive experience for the end-user with modern interactivity demands by abstracting away many of the responsibilities previously assigned to users. Of course, this may increase complexity at the producer, but the output is worth it.
Cost-effective: Event-driven architecture is pushed based on the producer pressing the message in the queue and the consumer receiving it. This way the continuous polling to check an event is not required. The CPU consumed is less, and the network bandwidth usage is reduced.
Advantages of serverless architecture:
It’s time to understand how these ready-made services can help reduce time-to-market ideas quickly and save us from the hassle of managing things other than our product.
Setting up and managing the environment: This step is not needed here. Usually, service providers provide consoles or SDKs to upload a piece of code. Then, this code is provisioned and deployed onto their servers. Also, other BaaS services like database, BLOB storage can be seamlessly accessed via some authentication mechanism.
Security: Unlike traditional approaches, the network configurations and security layer are inherently managed by service providers. These network configurations are well tested and not exposed to the end-user. Any security flaws are easily patched without us even noticing.
High level of granularity: With serverless architecture, applications are broken down into smaller pieces. This makes it easier to fix bugs and faster code deployments without downtimes.
With serverless, the organisation is not involved in the management of servers or databases. Hence organisations can save on the considerable investment they had to make earlier for Internal architecture administration.
Scalability: Scalability is one of the most attractive features of the serverless stack. It scales dynamically with increased traffic and also increases the number of concurrent executing functions. This is possible as operations are smaller and can be loaded into any of the free executors available. In contrast, this was difficult earlier as the whole application needed to be loaded on memory.
Efficient usage: You pay only for the amount of computing time. So you are not charged a penny if there were zero usage in a month.
Candidates for migrating services into serverless architecture
Though serverless seems too appealing, not all applications can be run on serverless architecture. Here are some parameters which will help us select which applications can be used well on serverless architecture.
Short running workloads: Functions that are small and are expected to run quickly can be deployed on serverless architecture. For example, an image processing application will be a good fit for serverless architecture. More computational power can be provided or modified for faster execution. There is no need for a separate image processing server.
Rest APIs: Basic CRUD applications can be built serverless. We can’t directly build web services around the serverless stack. However, we can create API endpoints and map them to functions. These functions get triggered when users hit these endpoints. We can also map responses that these functions return.
Periodic triggers: Schedulers or CRON jobs can be scheduled without a dedicated server. The schedulers are accurate and trigger functions that execute code at reliable intervals or a specific time. An organisation that needs to generate a daily report at a particular time at night will be a good example—or doing periodic health checks of the servers.
Communication: Cloud providers provide notification services that can deliver event-based notifications to other applications or messages to users via SMS, email, mobile push notifications. So applications that maintain their servers can do away and readily use these services.
Storage: Storage options allow developers to store documents as per demand. Hence developers can tweak their applications to store documents using these services rather than storing files on a dedicated server.
Drawbacks of EDA:
Over-engineering: Sometimes, a straightforward API call between two services can serve the purpose, but if we are going with EDA, we require good infrastructure on both the ends (producer and consumer), i.e. queuing system, which will add additional costs. Secondly, instead of just focusing on business logic, the team also has an extra effort of reading events and validating the same.
Inconsistent behaviour: Update to the same event and duplication of an event makes the system more challenging to handle, making the system complex. This may also result in increased time for testing and debugging scenarios.
Error handling and troubleshooting: A typical application will generally have several message producers and consumers. Third-party tools might be required to be installed & configured to monitor the event flow effectively.
About Neebal:
Neebal, a technology solutions provider, has delivered top of the line solutions across Agro, Pharma, and BFSI verticals. Neebal aims to provide top tier services for API Integration, RPA, and advanced mobility with prime focus on Hyperautomation. Founded in 2010, Neebal is a proud recipient of the Deloitte Technology Fast 500 Award (APAC) and the Deloitte Fast 50 Award (India) for four consecutive years (2017-20).